
Keyword: k-means, クラスタ分析, cluster analysis, データマイニング
概要
本サンプルはk-meansクラスタリングを行うC言語によるサンプルプログラムです。 本サンプルは以下の「分析対象データ」に示される変数が5個、観察数が20のデータを分析対象とします。 このサンプルではk-means法によりデータを3つのクラスタに分割します。 また k-means 法で必要な初期値も以下の「与える初期値」に示す通り与えます。
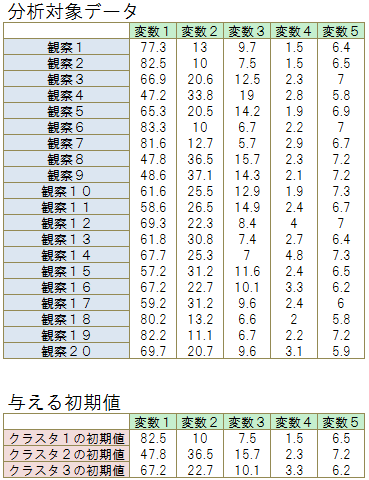
※本サンプルはnAG Cライブラリに含まれる関数 nag_mv_kmeans_cluster_analysis() のExampleコードです。本サンプル及び関数の詳細情報は nag_mv_kmeans_cluster_analysis のマニュアルページをご参照ください。
ご相談やお問い合わせはこちらまで
入力データ
(本関数の詳細はnag_mv_kmeans_cluster_analysis のマニュアルページを参照)| このデータをダウンロード |
nag_mv_kmeans_cluster_analysis (g03efc) Example Program Data U 20 5 5 3 10 77.3 13.0 9.7 1.5 6.4 82.5 10.0 7.5 1.5 6.5 66.9 20.6 12.5 2.3 7.0 47.2 33.8 19.0 2.8 5.8 65.3 20.5 14.2 1.9 6.9 83.3 10.0 6.7 2.2 7.0 81.6 12.7 5.7 2.9 6.7 47.8 36.5 15.7 2.3 7.2 48.6 37.1 14.3 2.1 7.2 61.6 25.5 12.9 1.9 7.3 58.6 26.5 14.9 2.4 6.7 69.3 22.3 8.4 4.0 7.0 61.8 30.8 7.4 2.7 6.4 67.7 25.3 7.0 4.8 7.3 57.2 31.2 11.6 2.4 6.5 67.2 22.7 10.1 3.3 6.2 59.2 31.2 9.6 2.4 6.0 80.2 13.2 6.6 2.0 5.8 82.2 11.1 6.7 2.2 7.2 69.7 20.7 9.6 3.1 5.9 82.5 10.0 7.5 1.5 6.5 47.8 36.5 15.7 2.3 7.2 67.2 22.7 10.1 3.3 6.2 1 1 1 1 1
- 1行目はタイトル行で読み飛ばされます。
- 3行目は重み付けをするかどうかを示すパラメータ (weight=U)、観察数 (n=20)、変数の数 (m=5)、計算で使う変数の数 (nvar=5)、 クラスタ数 (k=3)、最大計算反復回数 (maxit=10) を指定しています。 重みをつけるかどうかは重みをつけない指定である U が指定されています。変数の数と計算で使う変数の数は別々に指定できるようになっていますが、このサンプルでは与えたデータすべてを用いて計算を行うため変数の数と同じ数値である 5 が指定されています。クラスタ数は分割したいクラスタの数を指定します。今回は3つに分割をしたいので3と指定されています。最大計算反復数は最大で何回まで反復を行うかを設定しています。(計算が収束しない場合でも最大ここで指定する回数の反復が行われたら計算を終了します)
- 5行目〜24行目は観察データ(x)を指定しています。各行はそれぞれの観察値であり、5つ(3行目で示される変数の数)の値を持っています。
- 26行目〜28行目はクラスタ中心の初期値(cmeans)を与えています。各行は各クラスタに対応し、5つ(3行目で示される変数の数)の変数値が指定されています。
- 30行目は計算で使う変数がどれであるかを示すパラメータ(isx)を指定しています。ここで 1 は計算で使う事を示しています。(0は計算で当該変数を使わないことを示します。ここで与える数字は変数の数分なければなりません。また指定される1の数が計算で使う変数の数と一致している必要があります) 今回のデータはすべての変数を計算で使うので5つの 1 が与えられています。
出力結果
(本関数の詳細はnag_mv_kmeans_cluster_analysis のマニュアルページを参照)| この出力例をダウンロード |
nag_mv_kmeans_cluster_analysis (g03efc) Example Program Results
The cluster each point belongs to
1 1 3 2 3 1 1 2 2 3
3 3 3 3 3 3 3 1 1 3
The number of points in each cluster
6 3 11
The within-cluster sum of weights of each cluster
6.00 3.00 11.00
The within-cluster sum of squares of each cluster
46.5717 20.3800 468.8964
The final cluster centres
1 2 3 4 5
1 81.1833 11.6667 7.1500 2.0500 6.6000
2 47.8667 35.8000 16.3333 2.4000 6.7333
3 64.0455 25.2091 10.7455 2.8364 6.6545
- 1行目はタイトルです
- 4行目〜6行目には各観察データがどのクラスタに属するかが出力されています。 今回は3つのクラスタに分割していますので 1, 2, 3 のいずれかの数値が出力されています。 この出力では上から順番に
観察データ1=第一クラスタ
観察データ2=第一クラスタ
観察データ3=第三クラスタ
観察データ4=第二クラスタ
…
であることを意味しています。 - 9行目から10行目にはそれぞれのクラスタにいくつのデータが含まれるかが出力されています。 このサンプル出力では第一クラスタには6個、第二クラスタには3個、第三クラスタには11個のデータがそれぞれ含まれていることが示されています。
- 12行目から13行目にはそれぞれのクラスタの重みの合計が出力されています。 今回のサンプルデータでは重みづけを行わない設定 (つまり重みをすべて1.0として計算) ですのでデータの個数 x 1.0 が出力されています。
- 15行目から17行目にはそれぞれのクラスタの二乗和が出力されています。
- 19行目から23行目は最終的に求まったクラスタ中心が出力されています。 行方向がクラスタ、列方向が変数を表しています。
ソースコード
(本関数の詳細はnag_mv_kmeans_cluster_analysis のマニュアルページを参照)
※本サンプルソースコードはnAG数値計算ライブラリ(Windows, Linux, MAC等に対応)の関数を呼び出します。
サンプルのコンパイル及び実行方法
| このソースコードをダウンロード |
/* nag_mv_kmeans_cluster_analysis (g03efc) Example Program.
*
* CLL6I261D/CLL6I261DL Version.
*
* Copyright 2017 Numerical Algorithms Group.
*
* Mark 26.1, 2017.
*
*/
#include <nag.h>
#include <stdio.h>
#include <nag_stdlib.h>
#include <nagg03.h>
#define CMEANS(I, J) cmeans[(I) *tdcmeans + J]
#define X(I, J) x[(I) *tdx + J]
int main(void)
{
Integer exit_status = 0, i, *inc = 0, *isx = 0, j, k, m, maxit, n, *nic = 0,
nvar;
Integer tdcmeans, tdx;
NagError fail;
char weight[2];
double *cmeans = 0, *css = 0, *csw = 0, *wt = 0, *wtptr, *x = 0;
INIT_FAIL(fail);
printf("nag_mv_kmeans_cluster_analysis (g03efc) Example Program Results"
"\n\n");
/* Skip heading in the data file */
scanf("%*[^\n]");
scanf("%1s", weight);
scanf("%ld", &n);
scanf("%ld", &m);
scanf("%ld", &nvar);
scanf("%ld", &k);
scanf("%ld", &maxit);
if (n >= 2 && nvar >= 1 && m >= nvar && k >= 2) {
if (!(cmeans = nAG_ALLOC((k) * (nvar), double)) ||
!(css = nAG_ALLOC(k, double)) ||
!(csw = nAG_ALLOC(k, double)) ||
!(wt = nAG_ALLOC(n, double)) ||
!(x = nAG_ALLOC((n) * (m), double)) ||
!(inc = nAG_ALLOC(n, Integer)) ||
!(isx = nAG_ALLOC(m, Integer)) || !(nic = nAG_ALLOC(k, Integer)))
{
printf("Allocation failure\n");
exit_status = -1;
goto END;
}
tdx = m;
tdcmeans = nvar;
}
else {
printf("Invalid n or nvar or m or k.\n");
exit_status = 1;
return exit_status;
}
if (*weight == 'W') {
for (i = 0; i < n; ++i) {
for (j = 0; j < m; ++j)
scanf("%lf", &X(i, j));
scanf("%lf", &wt[i]);
}
wtptr = wt;
}
else {
for (i = 0; i < n; ++i) {
for (j = 0; j < m; ++j)
scanf("%lf", &X(i, j));
}
wtptr = 0;
}
for (i = 0; i < k; ++i) {
for (j = 0; j < nvar; ++j)
scanf("%lf", &CMEANS(i, j));
}
for (j = 0; j < m; ++j)
scanf("%ld", &isx[j]);
/* nag_mv_kmeans_cluster_analysis (g03efc).
* K-means
*/
nag_mv_kmeans_cluster_analysis(n, m, x, tdx, isx, nvar, k, cmeans,
tdcmeans, wtptr, inc, nic, css, csw, maxit,
&fail);
if (fail.code != NE_NOERROR) {
printf("Error from nag_mv_kmeans_cluster_analysis (g03efc).\n%s\n",
fail.message);
exit_status = 1;
goto END;
}
printf("\nThe cluster each point belongs to\n");
for (i = 0; i < n; ++i)
printf(" %6ld%s", inc[i], (i + 1) % 10 ? "" : "\n");
printf("\n\nThe number of points in each cluster\n");
for (i = 0; i < k; ++i)
printf(" %6ld", nic[i]);
printf("\n\nThe within-cluster sum of weights of each cluster\n");
for (i = 0; i < k; ++i)
printf(" %9.2f", csw[i]);
printf("\n\nThe within-cluster sum of squares of each cluster\n\n");
for (i = 0; i < k; ++i)
printf(" %13.4f", css[i]);
printf("\n\nThe final cluster centres\n");
printf(" 1 2 3 4 5\n");
for (i = 0; i < k; ++i) {
printf(" %5ld ", i + 1);
for (j = 0; j < nvar; ++j)
printf("%8.4f", CMEANS(i, j));
printf("\n");
}
END:
nAG_FREE(cmeans);
nAG_FREE(css);
nAG_FREE(csw);
nAG_FREE(wt);
nAG_FREE(x);
nAG_FREE(inc);
nAG_FREE(isx);
nAG_FREE(nic);
return exit_status;
}