
時系列データの処理に優れた「リザバーコンピューティング (Reservoir Computing)」は、学習コストが低く、推論が高速であることから、エッジデバイスへの実装に適しています。
本記事では、産業用センサやIoTデバイスなど、計算リソースの制約が厳しく、かつノイズの混入が避けられない実環境での実装を想定し、nAG Library for Python (最適化ソルバー e04gn(handle_solve_nldf)) を活用した効果検証の結果をご紹介します。
nAGライブラリの高度な最適化アルゴリズムを活用することで、以下の成果が得られました。
- モデルの軽量化(スパースモデリング): L1正則化(Lasso)の適用により、精度に寄与しない結合を数学的に特定・排除。推論時における出力層の演算コストを約90%削減しました。
- 耐ノイズ性能(ロバスト回帰): SmoothL1損失関数の適用により、突発的なスパイクノイズの影響を最小限に抑制。外乱の多い環境下でも安定した推論を実現しました。
- 実装の効率化: 学習済みのモデルパラメータをC言語ヘッダとして出力し、マイコン等のエッジデバイスへスムーズに実装するフローを確立しました。
1. データの準備とリザバー変換
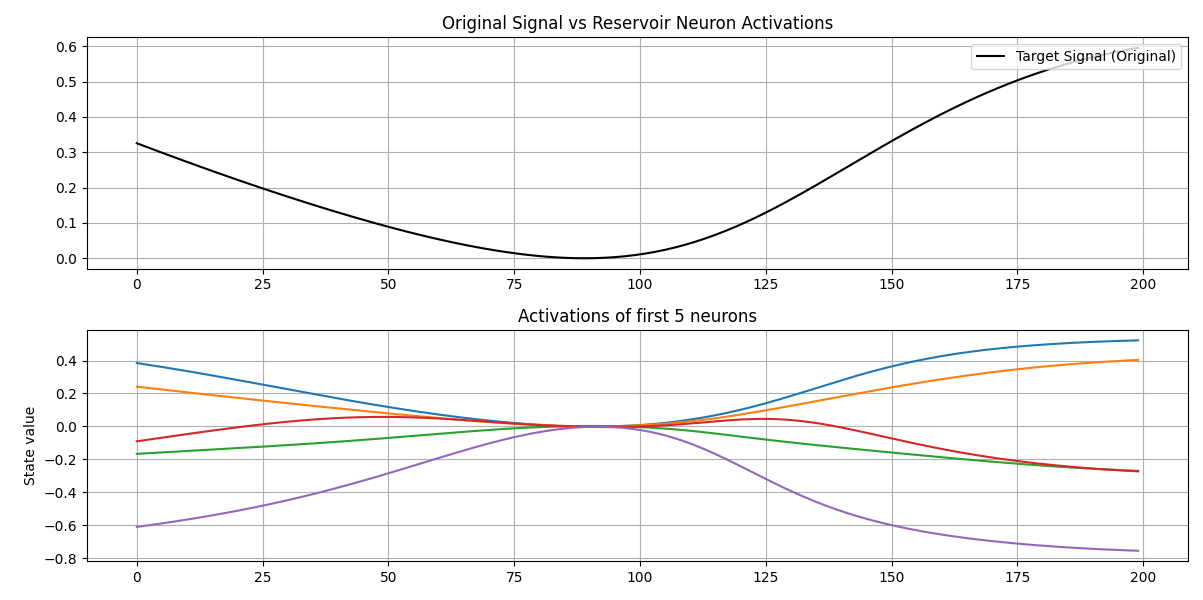
カオス時系列(Mackey-Glass方程式)を生成し、これを仮想的なセンサデータとして使用します。 リザバー層(中間層)により、単一の入力波形を高次元(本検証では50次元)の特徴量空間へ写像します。
使用したデータセット (mackey_glass.txt 抜粋):
2. スパース学習によるモデル圧縮
一般的な最小二乗法(リッジ回帰含む)では全ての結合荷重が非ゼロとなりますが、メモリ制限のあるエッジ実装においては計算資源の浪費となります。
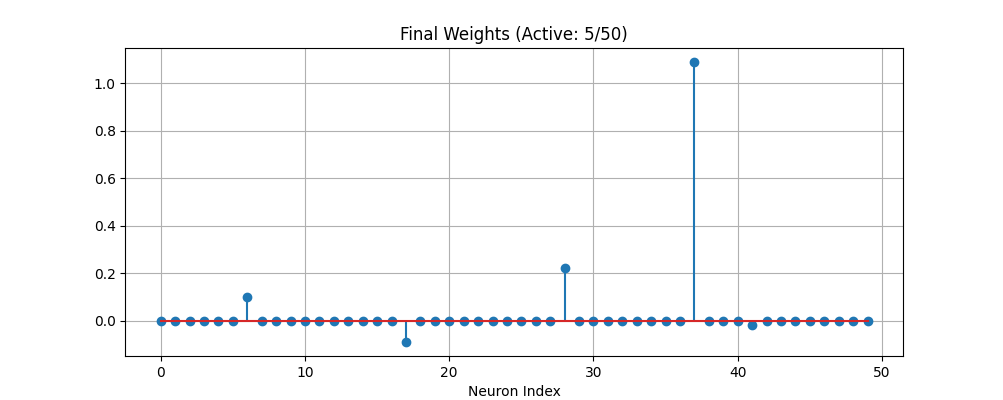
nAGの e04gnf (handle_solve_nldf) にて L1正則化 (Lasso) を適用し、モデルの精度を維持しつつ、不要なパラメータをゼロ化(スパース化)しました。
上段:予測波形(赤)は正解(黒)を高精度に追従しています。
下段:学習された重み係数。50個のパラメータのうち45個がゼロとなり、わずか5個のパラメータのみでモデルが構成されていることが確認できます。
(※一見すると4本に見えますが、右側(インデックス41)に非常に値の小さな5つ目の重みが存在します)
3. ロバスト性の検証
次に、現場で発生しうる「過酷なノイズ環境」を再現し、従来手法との比較を行いました。 入力データの一部に巨大なバーストノイズ(緑線)を混入させ、 一般的な「L2損失(青線)」と、nAGの「SmoothL1損失(赤点線)」で学習結果がどう変わるかを比較します。
参照コード: train_rc_robust.py
上段:入力データ。バーストノイズにより信号が激しく乱れています(緑線)。
下段:推論結果。L2損失(青線)はノイズに引きずられて波形が大きく歪んでいますが、SmoothL1損失(赤点線)は異常値を無視し、背後の正解(太いグレー線)に沿って正しい波形を維持しています。
4. エッジデバイスへの実装
Python環境で最適化されたパラメータ(スパースな重み行列)を、C言語のヘッダファイル params.h として出力します。
これにより、学習環境から組込みマイコン環境へのスムーズな移行が可能となります。
生成された params.h(抜粋):
推論コードの実装イメージ(C言語):